Why Redis is so fast?
Posted on: 1/15/2025 4:15:00 PM
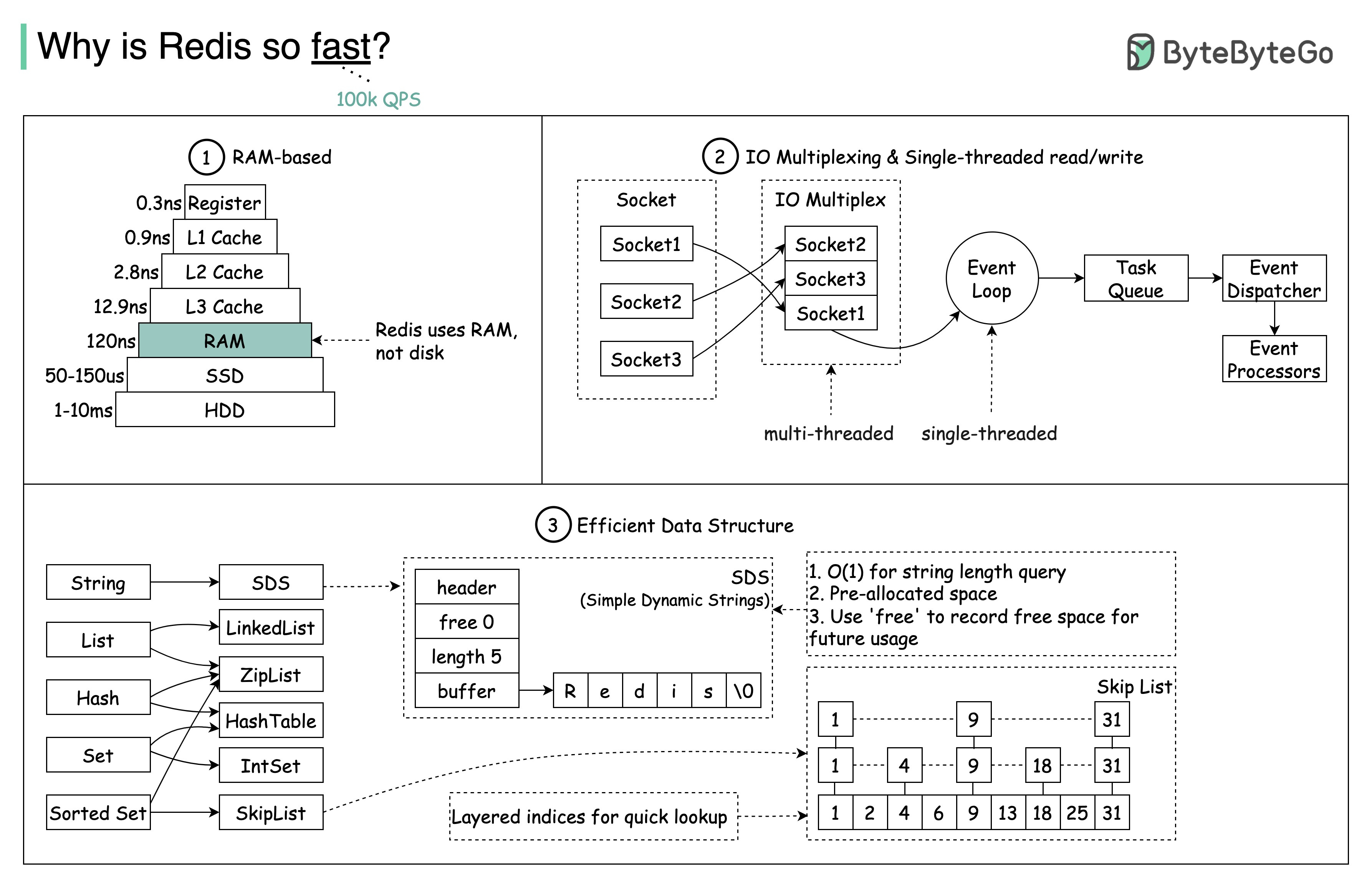
Redis (REmote DIctionary Server) is an extremely fast in-memory data store. Below are the reasons why Redis performs so well:
In-Memory data storage
- Redis stores all its data in RAM instead of on disk, allowing much faster data retrieval compared to reading/writing from disk.
- Storing data in RAM reduces latency to just microseconds when accessing data.
Optimized data structures
- Redis provides various data structures such as Strings, Lists, Sets, Hashes, Sorted Sets, Bitmaps, and more. These data structures are optimized for fast and efficient data processing.
Single-Threaded operation
- Redis uses a single-threaded model based on an event loop. This eliminates the overhead of thread synchronization or resource contention, ensuring high performance on the CPU.
No parsing or indexing overhead
- Redis avoids heavy tasks like query parsing or complex indexing. Data operations in Redis are direct and rely on built-in data structures.
Asynchronous I/O
- Redis uses an asynchronous I/O mechanism to handle requests, ensuring high performance even with many simultaneous connections.
Pipeline technique
- Redis supports pipelining, allowing multiple commands to be bundled into a single request, minimizing the number of client-server data exchanges.
Replication
- Redis supports replicating data to replica servers to distribute the load and enhance processing speed. Data can be served from replicas to reduce the load on the primary server.
Batch processing
- Redis supports commands to process multiple data items in one operation, such as
MGETandMSET, which help minimize execution time.
Compact data handling
- Redis compresses data efficiently to reduce RAM usage and optimize processing performance.
Optional snapshots and persistence
- Redis doesn’t require real-time disk writes, avoiding I/O-related latency. However, it can periodically take snapshots or log changes to ensure data durability when needed.
Support for efficient operations
- Redis offers bulk operations for certain commands and data types, further accelerating performance for high-throughput use cases.
References
Disclaimer: The opinions expressed in this blog are solely my own and do not reflect the views or opinions of my employer or any affiliated organizations. The content provided is for informational and educational purposes only and should not be taken as professional advice. While I strive to provide accurate and up-to-date information, I make no warranties or guarantees about the completeness, reliability, or accuracy of the content. Readers are encouraged to verify the information and seek independent advice as needed. I disclaim any liability for decisions or actions taken based on the content of this blog.